| 
在大模型项目研发过程中,数据划分是一项至关重要的工作。合理的数据划分策略可以帮助你更好地评估模型性能,同时避免模型的过拟合或欠拟合问题。本文将从数据划分的基本策略、常见问题及解决方案出发,详细介绍数据划分在大模型项目中的具体操作与注意事项。 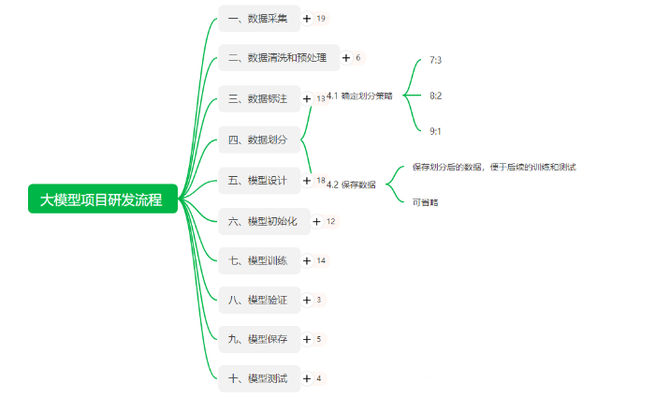
一、确定划分策略 数据划分的核心是如何合理地分配训练集和测试集,以保证模型训练的充分性与评估的准确性。常见的数据划分比例有 7:3、8:2 和 9:1,具体选择哪种比例取决于数据集的大小以及模型的实际需求。 1、7:3 比例 适用场景:当数据量较大且希望留出充足的测试数据时,7:3 比例是一种常见的选择。在这种划分下,70%的数据用于训练,30%的数据用于测试和验证。 优点: 测试集数据较多,能够更好地评估模型的泛化性能。 测试结果更具代表性,特别是在数据量大的情况下,这种比例可以有效检测模型在不同场景下的表现。 缺点: 留给模型训练的数据相对减少,可能导致在某些特征上模型学习不足,尤其是在处理小数据集时,模型可能无法充分学习到数据的特征。 技术细节:在应用这种比例时,务必确保测试集的数据具有代表性,涵盖了训练集中未出现的不同分布或边缘情况。常用的数据划分方法有 train_test_split 和交叉验证。 2、8:2 比例 适用场景:8:2 是最常用的划分比例,80%的数据用于模型训练,20%的数据用于测试。这种比例适合大多数机器学习项目,能够在训练和测试之间找到良好的平衡。 优点: 在确保测试集足够的前提下,模型训练数据量相对充足,适合大部分数据量适中的项目。 由于20%的测试集,模型评估的结果相对稳定,不容易出现较大的波动。 缺点: 如果模型表现依赖于某些边缘特征或极端数据,这部分数据可能会因测试集较小而难以评估到,导致模型实际应用中可能表现出不同于评估阶段的结果。 技术细节:建议对数据集进行多次划分,并结合交叉验证,以提高模型评估的准确性。 3、9:1 比例 适用场景:当数据集较小,或者模型对训练数据的依赖程度较高时,可以选择 9:1 的比例。90%的数据用于模型训练,10%的数据用于测试。这种比例适合需要最大化训练数据的场景,例如处理稀疏数据或高度复杂的模型。 优点: 最大限度地增加了训练集的数据量,能够提高模型的学习能力,尤其适合小数据集或复杂任务。 缺点: 测试集较小,评估结果可能会因为测试样本量不足而不够稳定,无法真实反映模型的泛化能力。 技术细节:建议在使用9:1比例时,增加模型评估的次数或采用交叉验证(K-Fold Cross Validation)以弥补测试集数据量不足带来的不稳定。 4、常见问题与解决方案 问题1:如何选择合适的划分比例? 解决方案:划分比例的选择主要取决于数据集的大小。如果数据量较大(如数百万条样本),可以选择7:3或8:2的比例,保证足够的测试数据来评估模型。如果数据量较小,则可以选择9:1的比例,以增加模型的训练数据。此外,可以通过交叉验证进一步提高模型评估的稳定性。 问题2:测试集过小导致评估结果不稳定怎么办? 解决方案:当测试集数据量过小时,建议使用交叉验证技术,尤其是 K 折交叉验证。通过多次划分数据集并对模型进行多次训练和评估,可以获得更稳定的模型表现结果。 二、保存数据 划分完数据后,如何保存这些数据是另一个关键步骤。合理保存数据不仅能够提高后续训练和测试的效率,还能为团队协作、结果复现提供保障。 1、 使用标准格式保存 保存划分后的数据时,建议使用常见的格式,如 .csv、.json、.h5 或者其他可供机器学习框架(如 TensorFlow、PyTorch 等)直接读取的格式。 这些格式文件不仅易于读取和操作,还可以在不同环境中轻松共享。例如,.csv 文件适合大部分基于表格结构的数据,而 .h5 文件则适用于需要存储大量数据的深度学习模型。 2、数据版本控制 在大型机器学习项目中,数据往往会经历多次变动或处理,可能因各种原因需要反复修改和重用。因此,使用数据版本控制工具来管理数据的不同版本是非常必要的。DVC(Data Version Control)是目前比较常用的工具之一,它能够帮助团队跟踪数据的变化,同时保证模型的可复现性。DVC 的基本操作: 通过 DVC,不仅可以对代码进行版本控制,还能够对数据进行版本控制,确保数据的每次变动都可以被追踪和恢复。 3、常见问题与解决方案 问题1:如何保证数据划分的可复现性? 解决方案:在划分数据时,务必设置随机种子(random seed),这样每次运行代码时,划分结果都是一致的。通过设置 random_state 参数,可以保证数据划分的一致性。 问题2:如何高效管理多次划分的数据集? 解决方案:建议使用 DVC 或者其他数据版本控制工具管理数据集,尤其是在数据处理流程较为复杂或者多人协作的项目中,版本控制工具能够极大地提高数据管理的效率与规范性。 三、总结 数据划分是大模型研发过程中至关重要的一步。本文详细介绍了常见的数据划分比例(7:3、8:2、9:1),并结合实际场景提出了不同划分策略的优缺点。我们还讨论了如何使用标准格式保存数据,以及如何通过数据版本控制工具(如 DVC)管理数据集的变化,确保项目的可复现性和协作效率。 无论你是在处理小型数据集还是大型复杂数据集,合理的数据划分策略和高效的数据保存方式都将帮助你在大模型项目中取得更好的成果。希望本文能够为你在数据划分和保存的过程中提供一些实用的指导与灵感。 为证券之星据公开信息整理股票质押专业融资,由智能算法生成,不构成投资建议。 为证券之星据公开信息整理,由智能算法生成,不构成投资建议。
|
